Multi-Project Architecture Guide
Welcome to the Multi-Project Architecture Guide!
This guide helps you effectively organize your Keboola projects, sharing successful strategies for clients of all sizes. You’ll learn about various project setups that meet your organizational needs and gain insights to tailor your Keboola projects for maximum efficiency and success.
Single Keboola Project
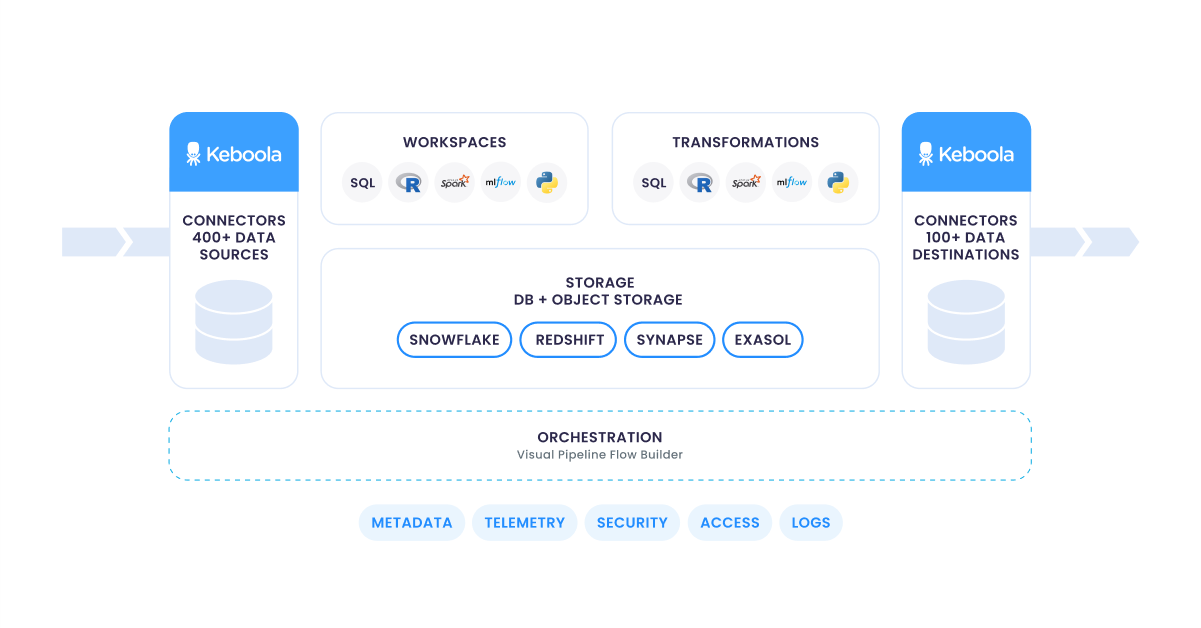
A Keboola project is the starting point for using the Keboola Platform, acting as a self-contained environment for managing access, data pipelines, storage, and processes. It provides a structured framework for distributing tasks and access across teams, ensuring efficient data governance.
Each project includes the following key components:
- Storage
- Relational databases such as Snowflake, Redshift, Synapse, Exasol, and others
- Object storage options like S3 or Azure Blob Storage
- Components
- Data sources and destinations for loading data into Keboola Storage and exporting to databases, services, or applications
- Applications for specialized tasks (data quality checks, NLP, etc.)
- Data templates for easy pipeline setup
- Transformations allow you to manipulate data for further use and consumption (SQL, Python, and R).
- Flows bring everything together as sets of tasks organized in workflows with assigned execution schedules.
- Governance layer covers metadata, telemetry, identity management, access control, etc.
For many organizations, a single Keboola project suffices indefinitely, supporting a comprehensive data stack for integration, transformation, pipeline orchestration, and analysis through SQL, Python, R, and visualization tools (e.g., Tableau, PowerBI, ThoughtSpot, and Qlik).
Organizations may transition to a multi-project architecture within Keboola as they evolve. This advanced structure allows for a scalable and sophisticated data solution by splitting responsibilities across multiple projects. This approach aligns with modern data management strategies, such as data mesh and democratization, by maintaining integrated yet isolated environments to avoid bottlenecks typically encountered with centralized BI teams.
Multi-Project Architecture (MPA)
MPA is a design strategy that divides data processing tasks among multiple function-specific Keboola projects. It transforms a single-project focus on Extract, Transform, and Load (ETL) processes into a structured data platform, enhancing organizational data management. This approach clarifies the role, simplifies access control, and supports tailored data usage and governance.
These are the key benefits of MPA:
- Defined Roles and Access: Facilitates role-specific access and responsibilities, ideal for diverse organizational needs.
- Purpose-Specific Projects: Assigns projects to specific functions like stable pipelines or experimental projects for clarity.
- Organized Data Processing: Segregates data pipeline stages into distinct projects for better structure.
- Team Collaboration: Allows team-specific project assignments, enhancing focus and collaboration. For instance, your marketing team may operate on a dedicated marketing project.
- Adaptable Infrastructure: Offers flexibility to meet changing organizational needs.
- Scalability and Future Growth: Prepares the architecture for scalable expansion and adaptability.
- Responsive Architecture Design: Enables agile adjustments to evolving data management requirements.
Assessing MPA Necessity
To determine if MPA suits your organization, consider the following:
- Do you want to separate data extraction?
Streamline data acquisition with a dedicated project (e.g., L0 or Staging project) to enhance collaboration. - Do you have diverse data sources? ne Process varying data sources (e.g., marketing, CRM, sales, accounting) in distinct projects for clearer management.
- Do you have unique team requirements?
Cater to different teams, branches, or country-specific needs with isolated projects. - Do you have specialist and consumer teams?
Can your team of specialists (e.g., BI team, data analysts) prepare core data in one project while data consumers access selected data assets via their dedicated projects? Balance data preparation and access between specialist and consumer projects. - Do you collaborate with external vendors?
Control data access for external vendors through dedicated projects. - What is your organizational structure?
Align projects with company domains, adopting a decentralized data management approach. - What is your team size?
For small, collaborative teams, minimize project numbers and focus on essential separations (perhaps only splitting the L0 layer by source/domain). - How to respond to failures?
Ensure that each project is isolated with a clear owner to resolve issues quickly. - Are there differences between regions/countries? Consider splitting projects based on regional differences to manage complexity. Evaluate whether maintaining the split on the L1 layer and merging at the L2 level provides a balanced approach.
- Do you use sensitive data?
Keep sensitive data separate for security reasons and to facilitate team management. Assess whether data masking is necessary at the L0 and L1 levels.
By addressing these questions, you can gain valuable insights into whether multi-project architecture aligns with your organizational structure, data processing requirements, and collaboration dynamics, ensuring a strategic and effective implementation of Keboola projects.
Designing MPA
Designing an MPA involves tailoring the architecture to fit the organization’s unique needs, data characteristics, and business operations.
Determine the optimal architecture based on the following:
- Data and business nature: Understand the data and business operations to identify domains and objects.
- Organizational structure: Align with the organization’s structure, focusing on data team roles and responsibilities.
- Data source diversity: Assess the need for project separation based on data source variety.
- Security: Consider data security, ownership, and compliance.
- Data volume and complexity: Evaluate the data’s volume and complexity to guide the design.
ⓘ Tip
A business data model (BDM) serves as the foundation, helping to group related objects within the MPA. It facilitates understanding business data and organizing projects around key domains, ensuring consolidation at appropriate levels (e.g., in L1/2).
See our BDM methodology guide for more information.
MPA Design Strategies
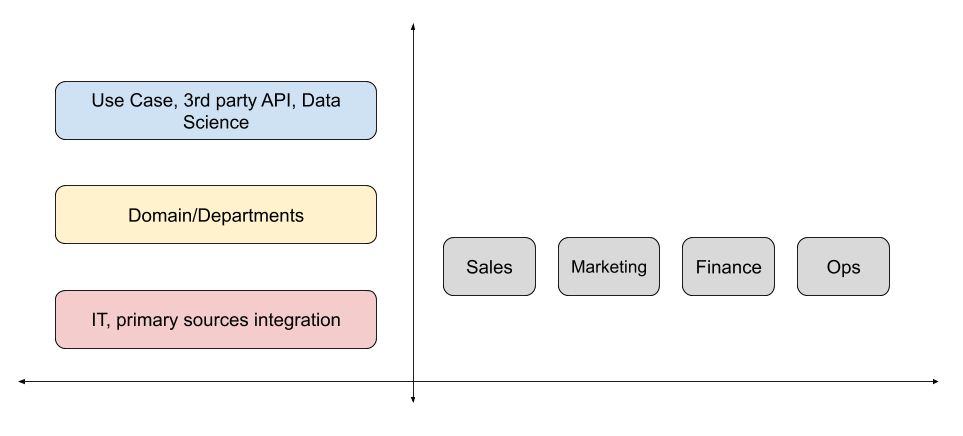
MPA designs typically follow a vertical, horizontal, or hybrid approach:
Vertical Split Design
The vertical split design assigns distinct pipeline stages to specific teams, typically reflecting the shift from core engineering/IT to business functions within an organization.
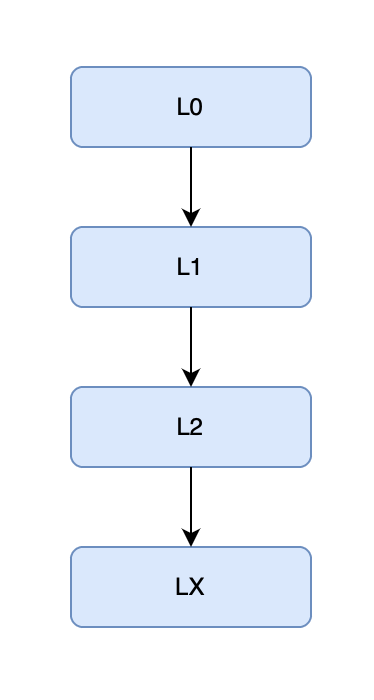
This strategy is common in enterprise settings, where IT teams design logical blocks of infrastructure (projects) into vertical projects, such as L0 for data acquisition, followed by L1, L2, etc., in Keboola’s framework. Each level represents a stage in data processing, ranging from acquisition, transformation, and blending to consumption.
Vertical split design is ideal when:
- Isolation isn’t required: No need for projects isolated to each data consumer or business user; the emphasis is on dividing data processing logically into separate layers.
- Managed by BI/data/IT teams: These teams oversee the entire data landscape, orchestrating processing and dataset availability for consumption.
- Centralized data access: Individual data consumers access datasets provided by the data team or via visualization tools linked to a specific database segment.
Key considerations:
- Layer-based structure: The architecture is organized into logical layers, with each team handling data processing tasks without overlap.
- Ownership by data team: The data team plays a pivotal role in managing and coordinating data across all layers.
- Managed data access: Access to data is regulated, with datasets either distributed by the data team or accessed via visualization tools connected to specific database parts.
Benefits:
- Efficient collaboration: Teams collaborate efficiently within their designated pipeline steps, streamlining processes and enhancing efficiency.
- Clear responsibilities: Responsibilities are clearly defined based on the logical layers, preventing confusion and promoting focused efforts.
- Centralized management: Centralized data management by BI, data, or IT teams ensures a structured and organized approach to data processing.
Considerations for implementation:
- Team alignment: Match team structures with data processing layers to enable specialization in their designated stage.
- Open communication: Create defined channels for team communication to enhance collaboration and information sharing.
- Continuous evaluation: Regularly assess and adjust the vertical split design to address changing business and data needs.
Note: This strategy excels in settings that benefit from centralized data management, where individual data consumers mainly interact with datasets curated by the data team.
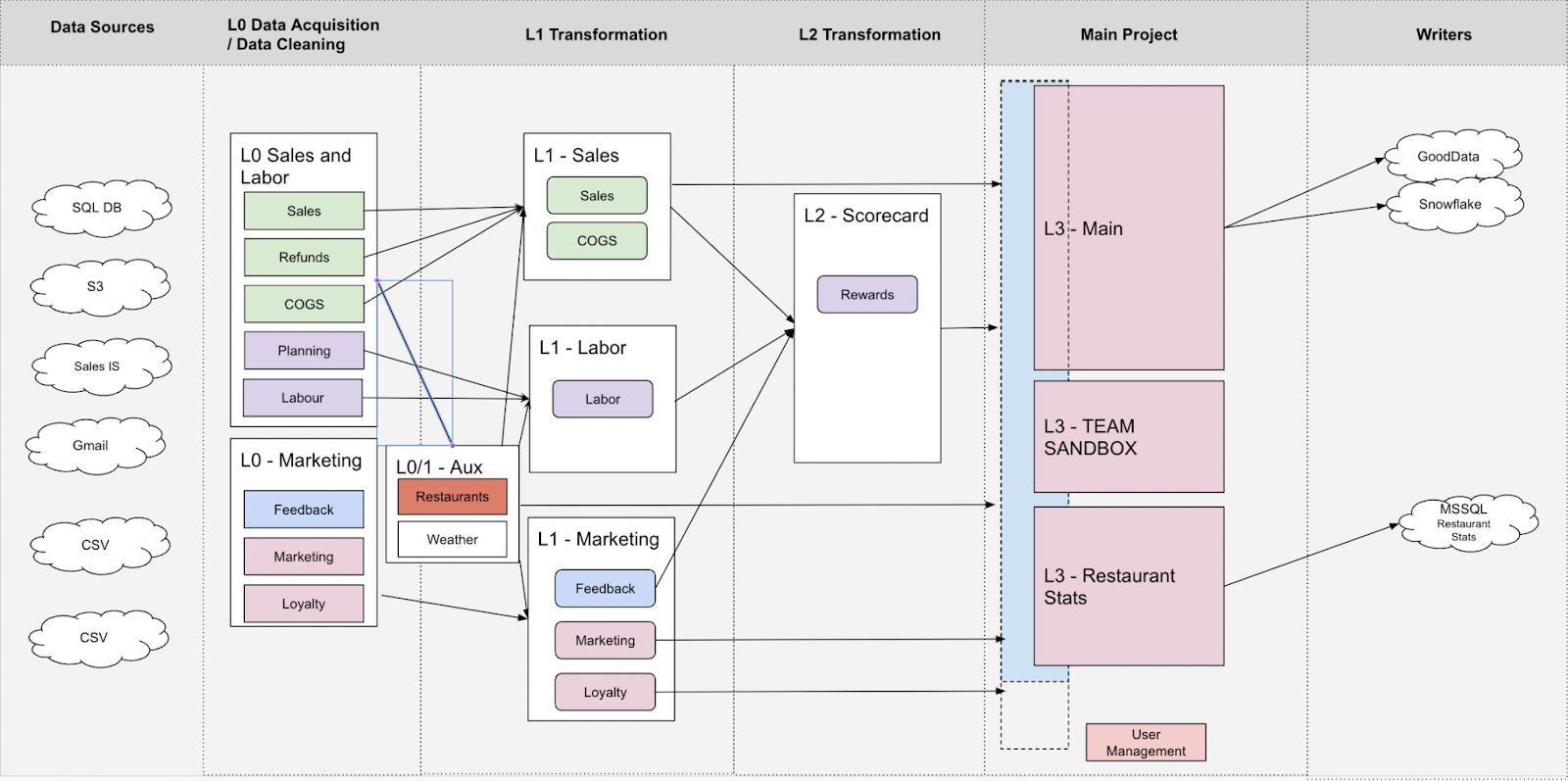
L0 – Acquisition
- Extracts data from Salesforce, Zendesk, MySQL database, Google Analytics, and Exponea.
- Performs initial data quality checks to ensure that extracted data is in the expected shape and quality.
L1 – Core Processing
- Integrates L0 data into a single model for further preparation and processing.
- Cleans and processes data for analysis.
L2 – Data Marts
- Hosts projects for creating data marts used by businesses and other users.
- Makes data accessible through visualization and reporting tools.
LX – Telemetry & Governance
- Maintains a dedicated project for analyzing Keboola’s telemetry and metadata for a comprehensive platform management and oversight.
Horizontal Split Design
The horizontal split design segments data pipelines and infrastructure by organizational units, such as departments and circles, enabling tailored data processing for distinct use cases. This setup allows each unit to oversee its data workflow independently using specialized knowledge. For example, the marketing departement can exclusively maintain a marketing data catalog, taking advantage of their domain knowledge.
Horizontal split design is ideal when:
- Entities operate independently: Suitable for units functioning autonomously with complete control over their data workflows.
- Use-case-specific infrastructure: Designed around unique needs, allowing units to tailor data pipelines to their requirements.
Key considerations:
- Departmental autonomy: Units independently manage their data tasks, from extraction to processing.
- Tailored to use cases: Infrastructure adapts to the specific data needs of each unit.
Examples:
- Sales and CRM
- Data extraction from Salesforce and a part of the MySQL database
- Full data processing, including eventual data testing
- Consumers access data directly in this project or via visualization and reporting tools connected to this project.
- Marketing
- Data extraction from Google Analytics, Exponea, and a part of the MySQL database
- Full data processing, including eventual data testing
- Consumers access data directly in this project or via visualization and reporting tools connected to this project.
- Operations
- Data extractions from Zendesk and a part of the MySQL database
- Full data processing, including eventual data testing
- Consumers access data directly in this project or via visualization and reporting tools connected to this project.

Benefits:
- Autonomy for departments: Empowers each unit with control over its data processes, enhancing flexibility.
- Customized infrastructure: Infrastructure is customized based on specific use cases of each unit, ensuring precise data processing.
- Use of expertise: Departments apply their domain knowledge for optimal data management, accuracy, and relevance.
Considerations for implementation:
- Foster collaboration: Despite autonomy, promote inter-departmental communication for shared insights.
- Enforce data governance: Maintain consistency and standards across all units through governance practices.
- Plan for Scalability: Ensure the design can grow with the department’s expanding data needs.
Note: This approach excels when units can independently handle their data, aligning with specific departmental requirements and domain knowledge.
Hybrid Split Design
The hybrid split design combines vertical and horizontal approaches within the data environment, offering a versatile solution for organizations. It enables vertical segregation of data extraction and integration from processing and consumption while also allowing the horizontal split of one or more vertical layers to create isolated environments for individual business units, departments, or teams.
Hybrid split design is ideal when:
- Combined separation needs: Essential for separating data operations vertically and catering to specific business units, departments, or teams horizontally.
- Mix of autonomy and teamwork: Aims to balance independent workflows for various entities and collaborative efforts as required.
Key considerations:
- Combination of splits: Merges vertical and horizontal splits to create a nuanced and adaptable data architecture.
- Dedicated spaces: Provides individual business units, departments, and teams with unique data environments.
Benefits:
- Balanced independence: Balances individual data management needs (vertical split) with opportunities for cross-entity cooperation (horizontal split).
- Tailored environments: Customizes data processing environments to meet the requirements of each business unit or team.
Considerations for implementation:
- Define vertical layers: Ensure clear separation between the data extraction/integration and processing/consumption layers.
- Align horizontal splits: Match horizontal splits with specific business units, departments, or teams, ensuring that each has an isolated environment.
- Enable collaboration: Set up channels for smooth entity interactions.
- Ensure flexibility and growth: Plan for the design’s scalability and flexibility to adapt to future organizational changes.
Note: The hybrid split design adapts to the complex needs of organizations, blending the strengths of both vertical and horizontal structuring to create a dynamic, scalable data architecture.